
В Корее представили «AutoGNN», который выполняет инференс в 2,1 раза быстрее, чем NVIDIA RTX 3090, и тратит электроэнергию в 3,3 раза меньше, чем обычный процессор
- 6 февр.
- 3 мин. чтения
Корреспондент Гу Бон Хёк
- Команда под руководством профессора Чон Мён Су, факультет электротехники и информатики
- Решает проблему «предварительной обработки данных»

Профессор Чон Мён Су (нижний ряд слева, против часовой стрелки), Кан Сын Кван, Ли Сын Чжун (аспиранты), Ли Сан Вон, Чан Чжун Хёк и Квон Ми Рён (исследователи Panmnesia). [Предоставлено KAIST]
Корейская исследовательская группа разработала технологию полупроводников для искусственного интеллекта, которые в 2,1 раза быстрее, чем графический процессор NVIDIA по скорости инференса, со существенно низким энергопотребления.
5 февраля Корейский институт передовых технологий (KAIST) сообщил, что исследовательская группа во главе с Чон Мён Су, профессор факультета электротехники и электроники и по совместительству гендиректор компании Panmnesia (веб-сайт https://panmnesia.com), впервые в мире разработала технологию полупроводников для искусственного интеллекта «AutoGNN», позволяющую существенно увеличить скорость инференса на основе графовых нейронных сетей искусственного интеллекта.
Исследовательская группа установила, что основная причина задержек в сервисе заключается в этапе предварительной обработки графа, предшествующем инференсу искусственного интеллекта. Этот процесс занимает 70–90 % общего времени вычислений, но существующие графические процессоры имеют ограничения в обработке сложных реляционных структур, что приводит к возникновению узких мест.
Для решения этой проблемы группа разработала адаптивную технологию ускорения искусственного интеллекта, которая динамически перенастраивает внутреннюю схему полупроводника в режиме реального времени на основе структуры входных данных. Такой подход позволяет полупроводнику автономно перенастраиваться в наиболее эффективную структуру, адаптированную к схемам связей анализируемых данных.
Команда реализовала два модуля в полупроводнике: модуль UPE, который выбирает только необходимые данные, и модуль SCR, который быстро организует и агрегирует их. При изменении объема или формы данных автоматически применяется оптимальная конфигурация модулей, что обеспечивает стабильную производительность в любых условиях.
Оценка производительности показала, что AutoGNN достигает скорости обработки в 2,1 раза выше, чем высокопроизводительный графический процессор NVIDIA (RTX 3090). По сравнению со стандартными процессорами он продемонстрировал в 9 раз более высокую производительность при снижении энергопотребления в 3,3 раза.

AutoGNN от KAIST. Изображение сгенерировано искусственным интеллектом [Предоставлено KAIST]
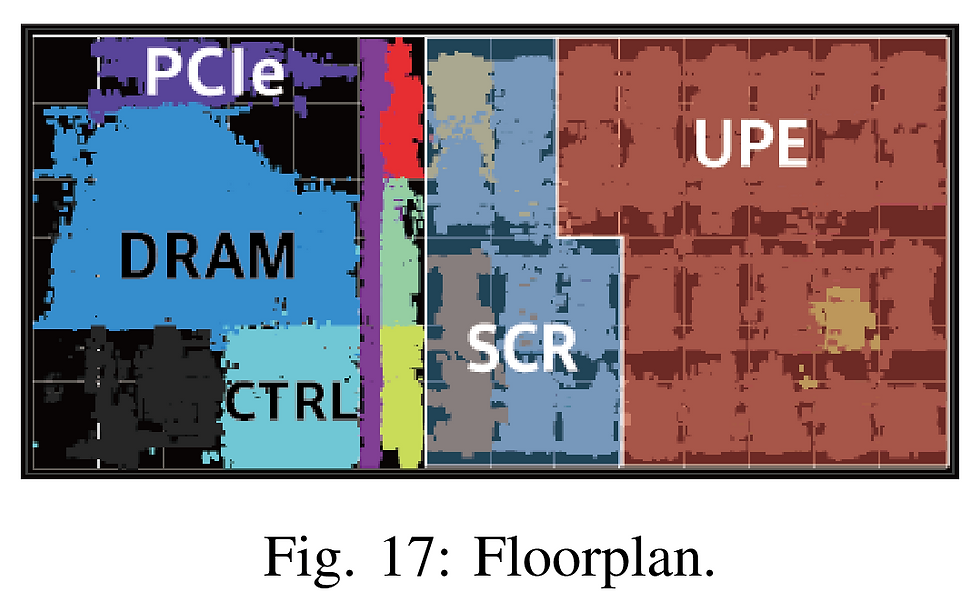
Рис. 1. Планировка новоразработанного полупроводника

Рис. 2. Обобщенное представление AutoGnn

Рис. 3. Структура ядра UPE

Рис 4. Структура ядра SCR

Рис 5. Общая время задержки. Остальные три системы — AutoPre, StatPre и DynPre — являются вариантами AutoGNN, каждый из которых выполняют «сквозную» предобработку GNN на FPGA. Они различаются по способу организации области UPE для двух этапов (упорядочивание и выбор) и по тому, являются ли аппаратные ядра перенастраиваемыми. В AutoPre область UPE статически разделена на два фиксированных поддвига: UPE только для упорядочения и UPE только для выбора, каждый из которых обеспечен равными бюджетами LUT. В этой конструкции намеренно отказались от возможности унификации UPE, сохранив оба этапа-специфических пути передачи данных, но два этапа по-прежнему выполняются последовательно из-за зависимостей. StatPre использует всю область UPE в режиме временного мультиплексирования для упорядочения и выбора. Повторное использование UPE, которое использует большую часть (70%) ресурсов FPGA, улучшает общее использование ресурсов по сравнению с AutoPre. DynPre дополнительно использует частичную перенастройку для адаптации компонентов UPE и SCR к целевому набору данных во время выполнения.
Эта технология может быть немедленно применена в ИИ-сервисах, требующих сложного анализа взаимосвязей и быстрого реагирования, таких как системы рекомендаций или обнаружение финансового мошенничества. Благодаря обеспечению технологии ИИ-полупроводников, которые самооптимизируется в соответствии со структурой данных, заложена основа для одновременного повышения скорости и энергоэффективности будущих интеллектуальных сервисов, обрабатывающих большие объемы данных.
«Это исследование имеет большое значение, поскольку в нем реализована гибкая аппаратная система, способная эффективно обрабатывать нерегулярные структуры данных» - сказал профессор Чон Мён Су, добавив: «Оно будет использоваться не только в системах рекомендаций, но и в различных областях искусственного интеллекта, требующих анализа в реальном времени, таких как финансы и безопасность».



Комментарии